Wstęp do teorii kompilacji

Kilka lat temu postanowiłem: napiszę swój język programowania! Wtedy jeszcze nie wiedziałem, na co tak na prawdę się piszę. Kiedy dowiedziałem się jak dużo nauki jest jeszcze przede mną, poczułem się jak Gandalf stojący naprzeciw Balroga. Kiedy pierwsza fala ekscytacji pomysłem ustała, rozpocząłem proces nauki. Czas zacząć układać sobie wiedzę zdobytą na ten fascynujący temat. Zapraszam na wstęp do teorii kompilacji :)
Od kodu źródłowego do pliku wynikowego
Na samym początku nie zdawałem sobie zupełnie sprawy z tego, czym kompilacja tak na prawdę jest. Wiedziałem, że są jakieś instrukcje preprocesora, oraz że kod przetwarzany jest na instrukcje assemblera. Tyle. Bardzo mało wiedziałem.
Dzisiaj wiem, że proces kompilacji składa się z kilku etapów, które następują po sobie. Wiem, czym jest preprocesor, oraz to, że jest uruchamiany na samym początku. Po przygotowaniu przez niego kodu, ten trafia do kompilatora, który najpierw analizuje go i przetwarza, a następnie optymalizuje. Na samym końcu wszystkie przekompilowane jednostki są łączone w jeden plik wynikowy.
Zobrazować ten proces można następująco:
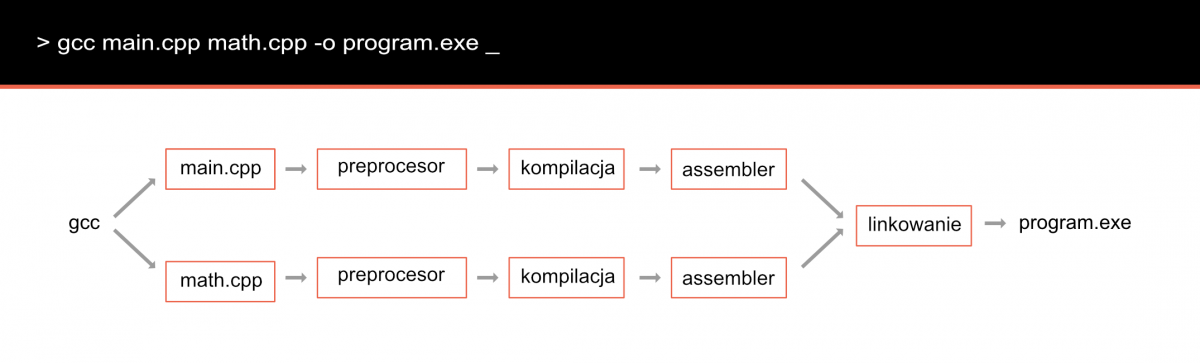
Kompilator a sterownik kompilacji
Zanim przejdę do krótkiego omówienia poszczególnych etapów kompilacji, wyjaśnić należy jedną rzecz. Kiedy ja uczyłem się C++, bardzo często słyszałem że po kliknięciu przycisku “Kompiluj” kompilator skompiluje mój program. Myślę, że często jest to celowy zabieg upraszczający, aby nie robić niepotrzebnego szumu informacyjnego. Jednakże jest to zbyt duże uproszczenie i nie należy go stosować omawiając proces kompilacji.
Cały proces, który tutaj omawiam, kontrolowany jest przez sterownik kompilacji. Jest to program kontrolujący cały proces kompilacji. Korzysta on z zestawu oprogramowania, który pozwala na przetworzenie kodu źródłowego na plik wynikowy. Jednym z programów zawartych wewnątrz tego zbioru jest właśnie kompilator, który przetwarza pliki z kodem źródłowym na kod assemblera.
Etap 0: Start procesu
Procesowi kompilacji poddawany jest każdy plik źródłowy z osobna. Oznacza to, że każdy plik źródłowy staje się całkowicie odseparowaną jednostką kompilacji. Dopiero pod koniec całego procesu pliki są łączone ze sobą.
Etap 1: Preprocesor
Pierwszym etapem procesu kompilacji jest preprocessing. To w tym momencie zostają dołączane wszystkie wymagane przez plik źródłowy nagłówki. Realizowane jest to poprzez rekursywne zastępowanie wszystkich instrukcji #include zawartościami plików, do których te instrukcje nawiązują.
Dodatkowo, w tym kroku odbywa się rozwiązywanie prostych składniowo makr znajdujących się wewnątrz plików źródłowych (instrukcja #define). Makra dają nam takie możliwości jak sterowanie procesem kompilacji w zależności od aktualnego środowiska, dodatkowe informacje debugujące, definiowanie własnych etykiet (dla stałych wartości) oraz upraszczanie bardziej skomplikowanych fragmentów kodu bez dodatkowego kosztu wydajnościowego. Niestety, są to zwykłe operacje podmiany, zatem błędy związane z typowaniem nie są tutaj wykrywane.
Po tym kroku wewnątrz wszystkich aktualne kompilowanych plików źródłowych nie powinno być już zawartych żadnych instrukcji preprocesora. Aby móc zatrzymać proces kompilacji w tym miejscu, należy do polecenia kompilującego przekazać przełącznik -E, na przykład:
gcc main.cpp calculations.cpp -E
Polecenie to w odpowiedzi zwróci na ekran przetworzony przez preprocesor kod. Jeżeli chcemy przekazać przetworzony kod do osobnego pliku, należy przekierować standardowe wyjście do pliku:
gcc main.cpp calculations.cpp -E > preprocessed.cpp
Ciekawostka: większość sterowników kompilacji pozwala na wymianę preprocesora, co daje stanowczo większe możliwości.
Etap 2: Diagnostyka
Kod przygotowany przez preprocesor trafia do kompilatora, który uruchamia pierwszy z trzech procesów: front-end. To front-end sprawdza kod pod kątem poprawności składniowej oraz semantycznej. Na tym poziomie generowane są błędy związane z niepoprawną składnią. Podczas procesu diagnostyki kod jest również sprawdzany pod względem semantyki, czyli sprawdzane jest to, czy instrukcje zawarte w kodzie mają sens. Przykładowy program z błędem semantycznym:
int main()
{
int a, b, c;
a + b = c;
}
Kiedy skompilujemy powyższy kod, mimo że jest poprawny składniowo, zwrócony nam zostanie następujący komunikat o błędzie:
error: expression is not assignable
a + b = c;
~~~~~ ^
Jak widać, kompilator nie dość że komunikuje nas o błędzie, to jeszcze wskazuje jego dokładną lokalizację. Jest to zasługa bardzo rozbudowanego systemu diagnostycznego, w który wyposażone są dzisiejsze kompilatory.
Analiza semantyczna polega na sprawdzeniu takich warunków jak¹:
- zgodność typów zwracanych przez funkcje
- poprawność typów użytkownika
- sensowność rzutowania
- promocje typów
- zgodność wyrażeń z interfejsami klas
Kiedy front-end nie wykryje żadnego zagrożenia, kod zwrócony przez preprocessor zostaje zamieniony w tzw. postać reprezentacji wewnętrznej, która trafia do kolejnego kroku.
Etap 3: Optymalizacja
Drugim procesem uruchamianym przez kompilator jest middle-end. To w tym miejscu generowane są drzewa AST. Przykładowe drzewo AST dla wyrażenia int a = 2 + 3; (forma tekstowa):
TranslationUnitDecl
`-FunctionDecl <line:3:1, line:5:1> line:3:5 main 'int ()'
`-CompoundStmt <col:12, line:5:1>
`-DeclStmt <line:4:5, col:18>
`-VarDecl <col:5, col:17> col:9 a 'int' cinit
`-BinaryOperator <col:13, col:17> 'int' '+'
|-IntegerLiteral <col:13> 'int' 2
`-IntegerLiteral <col:17> 'int' 3
Tutaj znajdziecie interaktywny przykład.
To na podstawie drzew składniowych przeprowadzane są optymalizacje. Przekształcenia optymalizacyjne mają za zadanie wygenerować kod niezmieniający zachowania optymalizowanych fragmentów, próbując przy tym zaoszczędzić m.in. na takich zasobach jak: czas wykonania operacji, zużycie pamięci oraz wielkość pliku wynikowego.
Dzisiejsze kompilatory udostępniają kilka flag, dzięki którym możemy sterować procesem optymalizacji:
-O0: optymalizacja czasu kompilacji (domyślna wartość)-O1lub-O: optymalizacja wielkości kodu oraz czasu wykonywania (poziom 1)-O2: optymalizacja wielkości kodu oraz czasu wykonywania (poziom 2)-O3: optymalizacja wielkości kodu oraz czasu wykonywania (poziom 3)-Os: optymalizacja wielkości kodu-Ofast: optymalizacja-O3z dodatkowymi optymalizacjami obliczeniowymi
Więcej informacji na temat przełączników optymalizacji znajdziecie tutaj.
Uwaga. Niektóre zabiegi optymalizacyjne polegają na wyrzuceniu wyrażeń, które nic nie wnoszą do programu. Na przykład:
#include <iostream>
int main()
{
std::cout << "Start" << std::endl;
int j=0;
int i=0;
for (j=0; j<1000; j++) {
for (i=0; i<10000000; i++) {
}
}
std::cout << "End" << std::endl;
}
Kiedy skompilujemy powyższy kod z flagą -O0, to pomiędzy jedną a drugą instrukcją wypisującą tekst wykonają się dwie pętle (trwa to wystarczająco długo, by zauważyć moment ich wykonywania). Po włączeniu flagi -O1 obydwa teksty zostaną wypisane natychmiastowo, co świadczy o tym, że instrukcje z pętlami zostały wyrzucone przez kompilator w trakcie procesu optymalizacji.
Etap 4: Wygenerowanie kodu assemblera
Ostatnim zabiegiem przeprowadzanym przez kompilator jest przełożenie kodu reprezentacji wewnętrznej na kod assemblera (assembly). Gdyby ktoś nie wiedział, to assembly jest bardzo trywialnym językiem programowania, który operuje na poziomie rejestrów oraz instrukcji zrozumiałych przez procesor. Jest to najniższego poziomu język programowania, w którym nie ma pętli ani klas. Są za to rejestry, w których możemy przechowywać wartości oraz przeprowadzać na nich bardzo proste operacje.
Aby zatrzymać proces kompilacji zaraz po wygenerowaniu kodu assemblera, należy do polecenia kompilującego przekazać przełącznik -S. Na przykład:
// main.cpp
int main()
{
int a = 10;
a++;
return a;
}
Po wydaniu polecenia gcc main.cpp -S wygenerowany zostanie plik main.s z kodem assemblera:
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 10, 14
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl $0, -4(%rbp)
movl $10, -8(%rbp)
movl -8(%rbp), %eax
addl $1, %eax
movl %eax, -8(%rbp)
movl -8(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbols
Jak na pierwszy rzut oka widać, nie wygląda to już tak prosto. Jest tak, ponieważ jest to kod przypominający już nieco schemat działania procesora.
Etap 5: Wygenerowanie pliku obiektowego
Przedostatnim krokiem procesu kompilacji jest przetworzenie kodu assemblera na kod maszynowy, zrozumiały dla systemu operacyjnego. Na jego podstawie generowane są pliki obiektowe, będące wyjściem dla jednostek kompilacji. Są one zbliżone budową do plików wykonywalnych - z tą różnicą, że pliki obiektowe nie posiadają referencji do wykorzystywanych symboli. Na tym etapie poszczególne jednostki kompilacji nie wiedzą nic o sobie wzajemnie, dlatego nie mogą określić pochodzenia wykorzystywanych wewnątrz siebie symboli.
Aby zakończyć proces kompilacji na tym etapie, należy w linii poleceń podać przełącznik -o, po którym należy podać ścieżkę do pliku wyjściowego (obiektowego). Przykładowe polecenie:
gcc main.cpp calculations.cpp -o program.o
Jak można zauważyć - do jednego pliku obiektowego możemy skompilować wiele plików źródłowych.
Etap 6: Linkowanie
Jest to ostatni krok podejmowany przez sterownik kompilacji. Na tym etapie wszystkie pliki obiektowe łączone są w jeden plik wynikowy. W tym miejscu łączone są ze sobą tablice symboli oraz podejmowane są czynności sprawdzające istnienie użytych wewnątrz kodu symboli. Jeżeli choć jeden użyty w kodzie symbol nie zostanie znaleziony w pozostałych jednostkach kompilacji, zostanie to zgłoszone jako błąd linkera. W tym miejscu podejmowane są również optymalizacje, których nie można było przeprowadzić ze względu na wiedzy jednostek kompilacji o sobie wzajemnie.
Błędy, na jakie możemy liczyć w tym momencie to błędy związane z nieodnalezioną referencją do funkcji lub symbolu. Przeanalizujmy prosty przykład:
class K {
public:
int funName();
};
int main()
{
K k;
return k.funName();
}
Kod wyżej jest poprawny składniowo oraz semantycznie. Jedyne, co stanowi problem, to brak ciała metody K::funName(), ale mimo to kompilator poprawnie przetwarza kod, aż do momentu linkowania. Dlaczego tak się dzieje? Odpowiedź brzmi: ciało funkcji mogło zostać zdefiniowane w innym pliku - w odrębnej jednostce kompilacji. Dopiero na etapie linkowania okazuje się, że nigdzie nie można odnaleźć referencji do tej metody.
Po skompilowaniu tego przykładu otrzymamy następujący komunikat o błędzie:
Undefined symbols for architecture x86_64:
"K::funName()", referenced from:
_main in main.cpp.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
Zapamiętajmy: jeżeli korzystamy z zewnętrznych bibliotek i mamy podobny komunikat o błędzie, to na 100% czegoś nie załadowaliśmy poprawnie.
Jeżeli wszystko poszło zgodnie z planem, generowany jest plik wynikowy.
Rodzaje plików wynikowych
W świecie programistycznym kilka typów plików wynikowych biorących udział w procesie kompilacji. Oto najważniejsze z nich:
- plik wykonywalny - plik programu, który może być uruchamiany w środowisku systemu operacyjnego użytkownika
- plik obiektowy (jednostka kompilacji) - plik binarny stosowany jako wejście dla procesu linkowania
- biblioteka statyczna - plik binarny grupujący w sobie wiele plików obiektowych, dołączany do programu podczas procesu linkowania
- biblioteka dynamiczna - plik binarny będący odpowiednikiem biblioteki statycznej, dołączany do programu w momencie uruchomienia go w systemie operacyjnym użytkownika
Formaty plików wynikowych
Każdy z wyżej wymienionych typów plików wynikowych jest tak na prawdę zapisywany w dokładnie tym samym formacie (w obrębie tego samego systemu operacyjnego). W dzisiejszym świecie rozróżniamy trzy główne formaty plików wynikowych²:
- Mach-O - pliki wynikowe dla systemów OSX, MacOS oraz iOS
- PE (Portable Executable) - pliki wynikowe dla systemu Windows
- ELF (Executable and Linkable Format) - pliki wynikowe dla systemów z rodziny Unix
Więcej na temat formatów plików wynikowych poruszę w osobnym wpisie.
¹ Fragment zapożyczony z artykułu “Tajniki budowy kompilatorów języka C++” znajdującego się w magazynie “Programista 8/2014 (27)”
² Jest ich więcej, wymieniłem jedynie te najpopularniejsze.

Zawodowo backend developer, hobbystycznie pasjonat języka C++. Po godzinach poszerza swoją wiedzę na takie tematy jak teorii kompilacji oraz budowa formatów plików. Jego marzeniem jest stworzyć swój własny język programowania.







