Zarządzanie zasobami w C++ #3 – RVO, NRVO i obowiązkowe RVO w C++17

W poprzednich dwóch częściach tego cyklu artykułów wyjaśniliśmy sobie rzeczy, które powinny być podstawą podczas pisania eleganckiego kodu w C++. W tej części przyjrzymy się bardziej niskopoziomowym aspektom języka związanym z zarządzaniem zasobami. Mogą być one jednak trudniejsze w zrozumieniu. Nie są jednak bardzo istotne z punktu widzenia programisty, dlatego nie polecam tego artykułu początkującym – mógłbym ich odstraszyć. Wszystkich innych zapraszam do lektury.
Dobra wiadomość jest taka, że twórcy standardu C++17 jedną małą sztuczką uprościli wiele zawiłości związanych z konstrukcją obiektów. Na początek przedstawimy te zawiłości (choć prawdopodobnie nie wszystkie), a potem porozmawiamy o rzeczonym rozwiązaniu.
Blok kodu
W wielu językach blok kodu jest rzeczą dość kosmetyczną, oddzielającą zbiór instrukcji od siebie. W C++ ma on jednak dużo szersze znaczenie. Widząc klamrę zamykającą (}) wprawiony programista widzi serię destruktorów, które są w tym miejscu niejawnie wywoływane. Oprócz nich widzi również zwolnienie na stosie całego zapasu pamięci, który w tym bloku został zarezerwowany. Oprócz szeregu pozytywnych konsekwencji z tym związanych, jak możliwość automatycznego z punktu widzenia programisty wywoływania destruktorów i kontroli użycia pamięci, są też pewne ograniczenia. Ograniczenia ściśle związane ze strukturą budowy stosu. Do stosu nie możemy nic “docisnąć” pomiędzy już zajęty obszar pamięci ani niczego wyrzucić ze środka – elementy muszą być usuwane “od szczytu”. Mimo to, stosując pewne optymalizacje, jesteśmy w stanie otrzymać pewną elastyczność przenoszenia zmiennych pomiędzy blokami kodu.
Referencje i przedłużanie życia obiektów
Załóżmy, że mamy klasę niekopiowalną i nieprzenoszalną (w bibliotece standardowej taką jest na przykład std::mutex):
class no_copymove
{
public:
no_copymove() = default;
no_copymove(const no_copymove&) = delete;
no_copymove(no_copymove&&) = delete;
no_copymove& operator=(const no_copymove&) = delete;
no_copymove& operator=(no_copymove&&) = delete;
};
Pomimo swoich właściwości, można obiekty tymczasowe, tworzone przez taką klasę, bezpiecznie przypisać do stałej referencji na ten obiekt:
const no_copymove& obj = no_copymove{};
Właściwość ta jest wbrew pozorom często wykorzystywana. Typową sytuacją tego typu jest przekazywanie łańcucha znaków opakowanych w std::string do funkcji:
void delete_file(const std::string& file_path);
int main()
{
delete_file("trash.txt");
return 0;
}
Przekazujemy tutaj do funkcji obiektu o typie const char*, podczas gdy funkcja spodziewa się const std::string&. Zostaje więc stworzona zmienna tymczasowa, a jej wartość przypisana do spodziewanej referencji. Gdyby referencja nie była stała, kompilator zaprotestowałby – po co mielibyśmy modyfikować obiekt tymczasowy? Oczywiście twórcy języka mogliby na to pozwolić, ale aktualne zachowanie bardziej chroni przed niepoprawnym użyciem funkcji. Jeżeli przyjmujemy coś przez niestałą referencję, to wyraźny znak, że chcemy tego użyć jako parametru wyjściowego (ang. output parameter).
Referencje do r-wartości
Podobnie jak zwykłe referencje, referencje do r-wartości również przedłużają czas życia obiektów:
no_copymove&& obj = no_copymove{};
Właściwość ta jest na pozór używana trochę rzadziej niż dla zwykłych referencji. Można ją jednak spotkać w definicji pętli for bazującej na zakresach (ang. range-based for loop), która rozwija się do następującego kodu:
{
auto && __range = range_expression ;
auto __begin = begin_expr ;
auto __end = end_expr ;
for ( ; __begin != __end; ++__begin) {
range_declaration = *__begin;
loop_statement
}
}
Dzięki temu taki kod jest poprawny, i nie wymaga kopiowania wektora:
std::vector<int> make_vector();
//...
for (int a : make_vector())
{
// kontener nie został zniszczony
}
Mimo że użycie referencji do r-wartości w ten sposób jest stosunkowo rzadko spotykane, możemy takiej konstrukcji użyć do wykonania pewnych optymalizacji. Zwłaszcza w połączeniu z innym, mało znanym mechanizmem…
Niuanse inicjalizacji klamrowej
W C++11 pojawiła się możliwość inicjalizacji zmiennej (wywołania konstruktora) przez klamerki ({}). Omówimy je tutaj krótko, aby mieć podstawy do dalszych rozważań.
Podstawowa składnia inicjalizacji klamrowej wygląda następująco:
std::string str1{"a"};
Taka inicjalizacja może przybrać trochę inną formę:
std::string str2 = std::string{"a"};
auto str3 = std::string{"a"};
Taka wersja inicjalizacji, zwłaszcza ze słowem kluczowym auto może wydawać się elegancka, gdyż podąża za najnowszymi trendami – najpierw podajemy nazwę zmiennej, a później jej typ. Do C++14 włącznie wymaga jednak, aby tworzony obiekt miał dostęp do konstruktora kopiującego lub przenoszącego. Gdyby czytać ten kod dosłownie, to mamy tutaj do czynienia z tworzeniem zmiennej tymczasowej, która zaraz jest przypisywana do nowego obiektu. Możemy się o tym przekonać, uruchamiając poniższy kod:
#include <iostream>
struct verbose {
verbose()
{
std::cout << "{ V() }";
}
~verbose()
{
std::cout << "{ ~V() }";
}
verbose(const verbose&)
{
std::cout << "{ V(const V&) }";
}
verbose(verbose&&) noexcept
{
std::cout << "{ V(V&&) noexcept }";
}
};
int main()
{
[[maybe_unused]] auto v = verbose{};
return 0;
}
Wynik uruchomienia tego programu zależy od tego, jakiego standardu C++ oraz jakich flag użyjemy. Jeżeli użyjemy standardu C++11 lub C++14 oraz zabronimy kompilatorowi wykonywania optymalizacji RVO (opisanej później), to wynik będzie następujący (GCC 9.2 z flagami -std=c++14 -fno-elide-constructors):
{ V() }{ V(V&&) noexcept }{ ~V() }{ ~V() }
Jeżeli nie będziemy na kompilatorze niczego wymuszać, tak czy siak cały ten proces zoptymalizuje, i żadne kopiowanie nie będzie miało tutaj miejsca. Bardziej szczegółowo przyjrzymy się temu w kolejnych rozdziałach.
Czasem można iść o krok dalej i pominąć nazwę tworzonego obiektu:
std::string str4 = {"a"};
Konstrukcji takiej możemy użyć, jeżeli wiemy jakiego typu obiektu się spodziewamy. Co ważne, ten typ inicjalizacji nigdy nie wywołuje (ani nie wymaga) konstruktora kopiującego. Zobaczmy przykład:
#include <iostream>
struct verbose {
verbose()
{
std::cout << "{ V() }";
}
~verbose()
{
std::cout << "{ ~V() }";
}
verbose(const verbose&)
{
std::cout << "{ V(const V&) }";
}
verbose(verbose&&) noexcept
{
std::cout << "{ V(V&&) noexcept }";
}
};
int main()
{
[[maybe_unused]] verbose v = {};
return 0;
}
Wynik takiego programu będzie zawsze taki sam, niezależnie od flag kompilatora:
{ V() }{ ~V() }
Taką samą inicjalizację można wykonać na typie niekopiowalnym i nieprzenoszalnym:
no_copymove v = {};
Takiej inicjalizacji nie należy mylić z taką, gdzie spodziewanego typu nie znamy. W takim przypadku kompilator wydedukuje typ, jeżeli będzie to możliwe:
auto obj1 = {"a"}; // std::initializer_list<const char*>
auto obj2 = {}; // błąd, dedukcja niemożliwa
auto obj3 = {"a", 1}; // błąd, dedukcja niemożliwa
Nas interesuje jednak przypadek, w którym typu nie trzeba dedukować i jest on z góry znany. Pozwala nam to na wykonanie pewnej sztuczki…
Zwracanie z funkcji “przepisu”
Klamrowej inicjalizacji bez podania typu możemy użyć przy zwracaniu obiektu z funkcji.
no_copymove make_no_copymove()
{
return {};
}
Jeżeli używamy C++11 lub C++14, nie możemy jednak takiej funkcji użyć w następujący sposób:
no_copymove v = make_no_copymove();
Możemy co prawda wywołać tę funkcję, ignorując wartość zwracaną:
make_no_copymove();
…ale nie po to wywołujemy funkcję, aby nie móc skorzystać z obiektu, który ona “zwraca”. Prawda jest taka, że możemy, ale musimy wykorzystać do tego właściwości referencji, o których pisałem w poprzednim rozdziale. A mianowicie faktu, że referencje przedłużają czas życia obiektów (bez wymogu posiadania przez nie konstruktora kopiującego czy przenoszącego). Wynika z tego, że naszą przykładową funkcję możemy zawołać w następujący sposób:
const no_copymove& v1 = make_no_copymove(); // lub prościej:
const auto& v2 = make_no_copymove();
no_copymove&& v3 = make_no_copymove(); // lub prościej:
auto&& v4 = make_no_copymove();
Zwłaszcza przypisanie do referencji do r-wartości jest użyteczne, gdyż nie daje nam narzutu w postaci obowiązkowego modyfikatora const.
Trzeba przyznać, że zwracanie obiektu niekopiowalnego i nieprzenoszalnego z funkcji w C++11 (oraz C++14) jest dość “hakerskie”. Da się, ale szczerze powiedziawszy nie spotkałem się z nim w kodzie produkcyjnym i mogę zaryzykować stwierdzenie, że mało kto wie o tym sposobie. We wstępie wspomniałem, że standard C++17 drastycznie uprościł sprawę. Zobaczmy więc, w jaki sposób…
RVO
W procesie tworzenia obiektu na stosie moglibyśmy wydzielić 2 etapy:
- Przesunięcie wskaźnika stosu o odpowiednią liczbę bajtów (~
sizeof(T)); - Wypełnianie zaalokowanej w ten sposób pamięci lub uruchomienie konstruktora.
Wizualnie można by ten proces przedstawić jak na poniższej grafice:
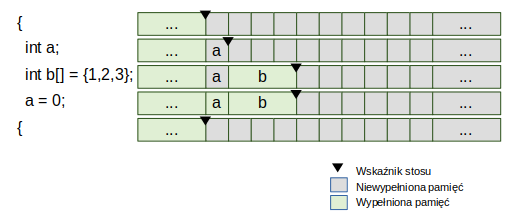
Cofnięcie wskaźnika stosu występuje jedynie przy opuszczaniu bloku kodu. Stos jest ciągłym obszarem pamięci, w którym żadne “luki” nie mogą mieć miejsca. Zobaczmy, jak wygląda podobny proces podczas wywoływania funkcji, która zwraca jakąś wartość:
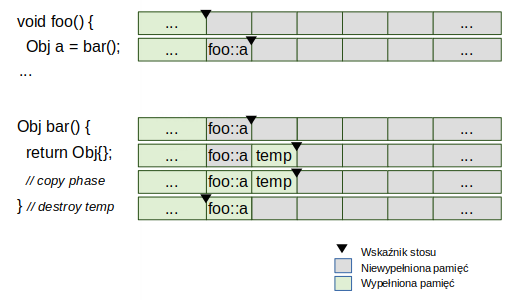
Standard C++ nie definiuje w żaden sposób, że stos podczas wywołania funkcji wygląda właśnie tak jak na rysunku. Definiuje to ABI (ang. Application Binary Interface) danego systemu operacyjnego albo architektury procesora. Nie mniej jednak tak to wygląda w najbardziej popularnych architekturach, jak 32- i 64-bitowe procesory x86 w systemach operacyjnych Windows czy Linux. Producenci kompilatorów już dawno wzięli pod lupę proces zwracania wartości z funkcji – w naszym przypadku return Obj{}; i doszli do wniosku, że można go uprościć. Zamiast tworzyć zmienną tymczasową (na grafice nazwaną roboczo temp) i wypełniać ją odpowiednią wartością, można by od razu użyć miejsca na stosie, wcześniej zarezerwowanego dla wartości zwróconej (a). Cały zoptymalizowany proces można zwizualizować w ten sposób:
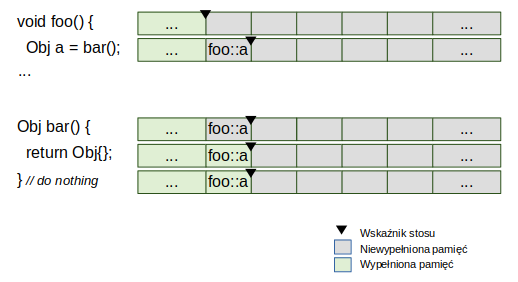
Postępując w ten sposób, nie tylko oszczędzamy miejsce na stosie. Przede wszystkim unikamy w ten sposób operacji kopiowania, która mogłaby być bardzo kosztowna. Nie zawsze chodzi tutaj bowiem tylko o odwzorowanie surowych bajtów w innym miejscu w pamięci, ale o wywołanie konstruktora kopiującego lub przenoszącego, jeżeli zwracany typ tego wymaga.
Opisana optymalizacja nazywana jest Return Value Optimization (w skrócie RVO) i do C++14 jest w każdej formie opcjonalna. Niesie to za sobą czasami niepożądane konsekwencje, ponieważ konstruktor kopiujący mógłby mieć jakieś efekty uboczne, które w zależności od użytego kompilatora mogłyby wystąpić lub nie. Z tego też powodu jedna z dobrych praktyk mówi, że:
Konstruktor kopiujący powinien zajmować się kopiowaniem i niczym więcej. W szczególności nie powinien posiadać żadnych efektów ubocznych, na których polega logika pisanego kodu.
Powyższa zasada, jak chyba wszystkie inne dotyczące dobrych praktyk może zostać złamana, ale musi być to w pełni świadome działanie programisty. Musi on zwłaszcza pamiętać o RVO.
NRVO
W poprzednim przykładzie celowo nie nadałem nazwy obiektowi zwracanemu z funkcji. Okazuje się, że gdyby zamiast pisać bezpośrednio:
Obj bar() {
return Obj{};
}
nadalibyśmy zwracanemu obiektowi nazwę:
Obj bar() {
Obj b{};
return b;
}
…to sytuacja się komplikuje. W tym momencie kompilator nie zawsze jest w stanie zagwarantować, że optymalizacja RVO jest możliwa. Dlaczego? Spójrzmy na trochę bardziej rozbudowany przykład:
Obj bar()
{
Obj odd_obj{1};
Obj even_obj{2};
return (std::time(nullptr) % 2 == 1) ? odd_obj : even_obj;
}
W podanym przykładzie tworzone są 2 obiekty, i nie jest z góry ustalone, który z nich zostanie zwrócony (uzależniliśmy to od aktualnego wskazania zegara). Dlatego też w momencie tworzenia obiektów nie możemy użyć wcześniej przygotowanego na stosie miejsca. Z tego też powodu powstało rozróżnienie i osobne określenie na optymalizację, która dotyczy zwracania obiektów nazwanych – NRVO (ang. Named Return Value Optimization).
Obowiązkowe RVO z C++17 i dlaczego nas to obchodzi?
Wraz z wejściem standardu C++17 do języka optymalizacja RVO, która nie jest NRVO, stała się obowiązkowa (NRVO nadal jest opcjonalna). Na pozór można by było się zastanowić, czy ta informacja dotyczy wszystkich programistów C++, czy jedynie twórców kompilatora. “Przecież to tylko optymalizacja” – można by rzec.
Otóż nie tylko. Jest to dodatkowe ułatwienie. Kod, który wcześniej się nie kompilował, może zacząć się kompilować po wprowadzeniu tej zmiany. Oto przykład takiego kodu:
std::mutex make_mutex()
{
return std::mutex{};
}
Obowiązkowe RVO spowodowało, że taki kod nie wymaga konstruktora kopiującego ani przenoszącego dla typu zwracanego. Powoduje to ogromne “poluźnienie” zasad związanych z przenoszeniem obiektów pomiędzy blokami kodu. O ile semantyka przenoszenia z C++11 pozwoliła nam zdefiniować, w jaki sposób ma wyglądać operacja przenoszenia obiektu pomiędzy blokami, to obowiązkowe RVO w wielu przypadkach pozwala nam całkowicie o tym zapomnieć.
Oznacza to też, że używając C++17 możemy zapomnieć o wszystkich tych (dość skomplikowanych) rzeczach, które opisałem w poprzednich rozdziałach. Od C++17, poniższe wyrażenia dają identyczny rezultat, niezależnie od użytych flag kompilatora:
no_copymove&& v = make_no_copymove();
no_copymove v = make_no_copymove();
auto v = make_no_copymove();
Jako ciekawostkę można dodać, że komitet ISO pracuje aktualnie nad pomysłem, aby również NRVO w niektórych przypadkach było obowiązkowe. Póki co jest to jednak pieśń przyszłości.
Almost Always Auto
Zanim przejdę do zakończenia, opiszę jeszcze jeden koncept, na który wpływ ma obowiązkowe RVO. Chodzi o AAA (ang. Almost Always Auto, Prawie Zawsze (używaj) Auto). Jest to dość kontrowersyjny styl pisania kodu, przedstawiony przez Herba Suttera, jednego z aktualnie najbardziej znanych ekspertów języka C++. Mówi on o tym, żeby pisać kod w ten sposób, żeby najpierw czytający go programista widział nazwę symbolu, która z założenia powinna być deskryptywna, a dopiero później jego typ. W języku C++ pomaga nam w tym słowo kluczowe auto. I tak zamiast pisać:
std::string userName{}; // (1)
std::shared_ptr<std::vector<std::string>> userNames
= std::make_shared<std::vector<std::string>>(); // (2)
std::string getUserName(); // (3)
Powinniśmy rozważyć pisanie kodu w następujący sposób:
auto userName = std::string{}; // (1)
auto userNames = std::make_shared<std::vector<std::string>>(); // (2)
auto getUserName() -> std::string; // (3)
Nie będę w tej chwili rozstrzygał, czy pomysł jest w każdym przypadku dobry, czy też nie. Mam jednak dobrą wiadomość dla tych, którzy taki styl na co dzień stosują. Mogą oni od C++17 zawołać w ten sposób dowolny konstruktor:
auto obj1 = std::mutex{};
auto obj2 = no_copyable_or_movable{"some args"};
Podsumowanie
Często twórcy C++ dodając nowe elementy do języka czynią go bardziej skomplikowanym. Obowiązkowe RVO jest chlubnym wyjątkiem. Wprowadzając kilka dodatkowych zapisów sprawili oni, że język stał się prostszy do zrozumienia – pozbył się kilku sytuacji brzegowych. Oby więcej takich zmian!
Czytaj poprzednie części
Zarządzanie zasobami w C++ #1 – RAII i wyjątki
Zarządzanie zasobami w C++ #2 – semantyka przenoszenia (std::move)

Entuzjasta języka C++, który to język poznaje od 14 roku życia. Uważa, że za używanie zwrotu "C/C++" powinno się wsadzać do więzienia. Prywatnie lubi grzybobranie, klimaty ogniskowe, Bieszczady, śpiewanie klasyków.









